Sample size re-estimation based on conditional power(1)
1. 背景
感觉好久没有正经的去研究一个topic了,上次研究一个Juicy的topic(Group Sequential )已经接近1年前了-_-||,人果然还是应该趁着年轻的时候多搞点东西,年纪大了就容易犯懒,什么都不想去做。言归正传,看看这次想补齐哪一块拼图呢?
背景是这样,去年在搞一个确证性临床的试验设计的时候,我初步提了一个sample size re-estimation based on variation under blinded situation,不过后面的讨论环节结合EOP2的实际情况,将疗效的预估降低了一些,老大顺势又说出“I am rich”,所以将这个设计删掉了,所以我在想不如趁机补齐这一块拼图,进而完善一下自己的知识体系。
我想参与过临床试验每一位同学应该都产生过类似的朴素的观念,在临床试验入组到一定受试者的时候,我想知道这个药物的疗效初步看到底怎么样,和我的预期相差多少、能否满足最基本的临床意义,我们要不要继续做下去?有些同学可能会兴冲冲的拿着小本本去找统计师,想立马看到结果,用来指导后续的临床试验?统计师笑眯眯的给你解释了一堆,从一类错误的膨胀讲到监管的考虑,从临床试验完整性扯到GCP,甚至拿出临床试验失败来吓唬你。其实呢,这些朴素的考虑可以转化为专业的术语,又叫做适应性设计,看看来自监管的定义[1]适应性设计允许根据试验期间累积的数据对试验设计进行修改,以修正初始设计的偏差,从而增加试验的成功率,提高试验的效率。当然最重要的是,是要提前在试验设计中明确规定并与监管达成一致。而样本量重估,就是依据临床试验某个时间点收集到的部分信息(如疗效的初步预估或数据变异情况等),在确保试验质量和控制Ⅰ类错误率的前提下,对预先设定的样本量进行重新评估并作出相应调整(通常为增加样本量,以提高统计把握度的一种方法),从而在试验进行过程中动态优化试验设计,提高成功率和资源利用效率。而我今天想讨论的内容就是在基于条件把握度的样本量重估,主要参考的是Mehta C R[2]的这篇文献,下面的正文大部分都是直接来源于文献中。
2. 统计方法
这个方法适用于两组设计,并可针对以正态、二分类及生存终点(以为涵盖了所有嘛?非也,还有recurrent data,这种数据以后再抽时间讲)为疗效指标的多阶段的成组序贯设计。现在我们假设有一个两阶段、两组(试验组和对照组)、终点为正态分布的临床试验的设计,试验组和对照组的终点各自服从X_{ej} \sim N\left ( \mu _{e},\sigma \right ) 和X_{cj} \sim N\left ( \mu _{c},\sigma \right ) 。疗效的差值则为\delta =\mu _{e}-\mu _{c}(高优指标,比如说是血压较基线的降低值),则有如下的单侧假设检验:
H_{0}:\delta =0
H_{1}:\delta >0
在上面提到的这个临床试验的设计中,我们分别用 图2.1 来代表各个阶段的样本量,如下所示:

图2.1
那么很容易就可以得出:n_{1} +\tilde{n}_2=n_{2}。下面我们用\hat{\delta}_{1} ,\hat{\delta}_{2} ,和\hat{\tilde{\delta} }_{2} 分别代表对应的n_{1},n_{2}和\tilde{n}_2疗效\delta的极大似然估计疗效,那么对应的Wald统计量分别为:
2.1 使用加权统计量进行样本量重估
当我们在 图2.1 中所示的节点进行期中分析时,有可能Stage Ⅱ和Final analysis的样本量会增加到如 图2.2 所示:
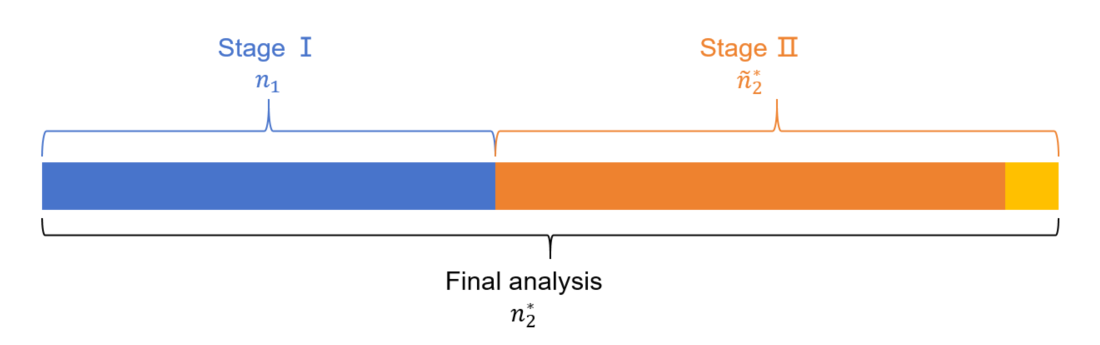
图2.2
我们分别用n_2^*和\tilde{n}_2^*来代表累计样本量与增量样本量。那么根据上面提到的(2)和(3)式,可以得出其对应的统计量分别为:Z_2^*和\tilde{Z}_2^*。有学者 Cui et al.[3]提出上述情形可能会导致Ⅰ类错误的膨胀,在其文章中指出无论Stage Ⅱ的样本量如何调整,如果使用CHW 统计量取代传统的Wald统计量Z_2^*,那么可以很好地控制Ⅰ类错误。如下所示:
尽管上式中很好的控制了Ⅰ类错误的膨胀,但是会降低中期分析后才纳入的部分新增受试者的权重(\tilde{n}_2^*>
\tilde{n}_2),在公式(4)中也有体现,即\tilde{Z}_2^*的权重与\sqrt{\tilde{n}_2}成正比,而不是\sqrt{\tilde{n}_2^*}。这与“所有的受试者平等”相矛盾。
2.2 使用传统统计量进行样本量重估
Chen et al.[4]研究表明,当期中分析的结果promising时,增加样本量并不会导致Ⅰ类错误的膨胀。具体而言,令:
上式代表条件检验效能(conditional power),也就是给定Z_1 = z_1时,在最终分析时拒绝原假设的条件概率为多少。因为\delta未知,所以用\hat{\delta}_{1} 来取代(5)式中的\delta。也就是说,条件检验效能的计算是假设期中分析时估计的疗效为真疗效。Bauer and Koenig[5]给出的计算方式如下:
Chen et al.[4]指出,当满足\mathrm{CP}_{\hat{\delta}_{1}}(z_1, \tilde{n}_2) \geq 0.5时,期中分析增加了样本量后,在最终分析时使用传统的统计量Z_2^*并不会导致一类错误膨胀。Gao[6]等人步进一步深入探讨了这一发现,并将其拓展到当 \mathrm{CP}_{\hat{\delta}_{}}(z_1, \tilde{n}_2)低于 50% 时的情形。至于CP具体能低于 50% 到何种程度,则取决于不同情境的具体设置,将在第 3.2 节中进行量化分析。
3. 一种简单的适应性增加样本量方法
为了能让适应性的调整样本量的方法更好的落地实施,那么需要更为简单、透明、便于理解和稳健的方法,让申办方更易进行操作实施。
3.1 定义适应性算法:一般原则
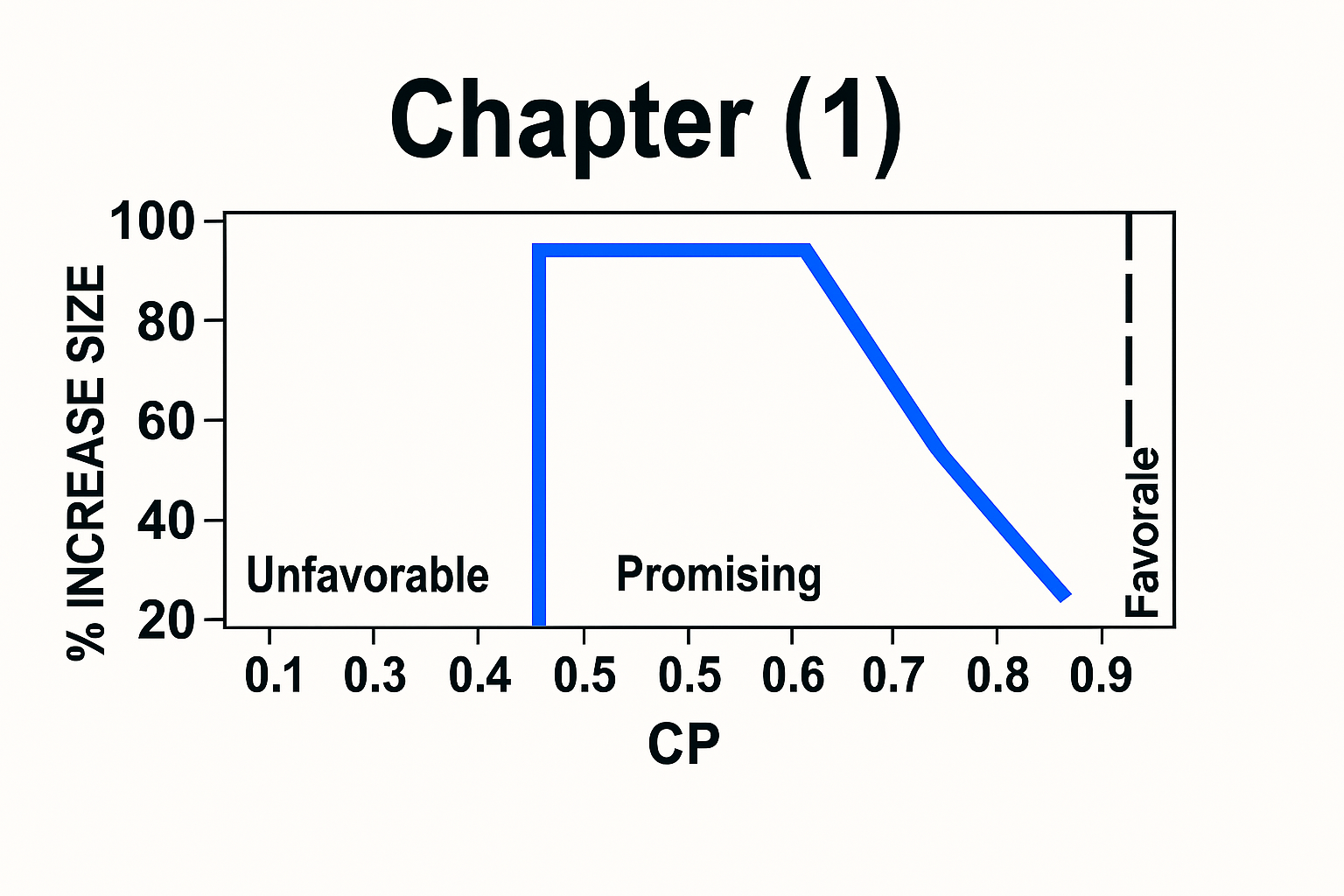
该方法的关键其实是在于评价期中分析时的CP,如果其过高或过低,那我们没有调整样本量的必要。然而如果CP处于一个期望区间,那么样本量是有可能增加用以使CP达到预设的水平。下表为一些参数的设置:
我们将\mathrm{CP}_{\hat{\delta}_{1} }(z_1, \tilde{n}_2)的可能的值分为三个区域:Unfavorable, Promising and Favorable。当CP在不同的区域时,依照下面的指南来进行样本量调整:
Unfavorable:当\mathrm{CP}_{\hat{\delta}_{1} }(z_1, \tilde{n}_2)< \mathrm{CP}_{\text{min}}时,定义为 unfavorable zone,此时\mathrm{CP}_{\text{min}}的值可以提前规定(比如30%或50%),也可以通过算法得出(如何计算在 3.2 章节),但通常是一个较低的概率,这一划分隐含着这样的认识:中期结果已经令人相当失望,进一步增加样本量来挽回(提升)条件功效并不值得。在此区域内,样本量无变化。
Promising:当\mathrm{CP}_{\text{min}} \leq \mathrm{CP}_{\hat{\delta}_{1} }(z_1, \tilde{n}_2) < 1 - \beta时,定义为promising zone。在这个区域内期中分析的结果虽不至于令人失望,但是也没有好到让CP等于或超过1-β。在这种情形下,样本量可以在不超过nmax的前提下,将样本量恰当地增加,来恢复到预期的把握度1-β。具体而言,那么新的样本量会增加到如下式所示:
n_2^*(z_1) = \min\left( n_2'(z_1), n_{\text{max}} \right) \tag{7}其中n_2'(z_1)满足条件
\mathrm{CP}_{\delta_1}(z_1, \tilde{n}_2') = 1 - \beta. \tag{8}通过简化(5)式子[6],可以容易得出(8)式满足:
\tilde{n}'_2(z_1) = \left[ \frac{n_1}{z_1^2} \right] \left[ \frac{z_\alpha \sqrt{n_2} - z_1 \sqrt{n_1}}{\sqrt{n_2 - n_1}} + z_\beta \right]^2 \tag{9}Favorable:\mathrm{CP}_{\delta_1}(z_1, \tilde{n}_2) \geq 1 - \beta定义为favorable zone。在这个范围内期中分析的结果足够好,不需要对样本量进行适应性的调整。请注意,这一有利区间不仅覆盖了所有\hat{\delta}_1 \geq \delta_1的情形,同时也向下延伸至略小于\delta_1的值;
3.2 论证使用传统最终分析的合理性
在先前的讨论中已经提到当期中分析的CP落在“promising zone”时,使用传统的统计检验可以很好的控制Ⅰ类错误的膨胀。现在主要来探究这个“promising zone”是怎样确立的。
Lemma 1
假设在期中分析时观察的Z_1=z_1,二阶段的样本量从\tilde{n}_2调整到\tilde{n}_2^*。无论用什么公式去计算\tilde{n}_2^*,均有
其中,
上式的证明在文献[6]中。请注意,如果样本量没有进行调整,那么\tilde{n}_2^* = \tilde{n}_2,Z_2^* = Z_2和b(z_1, \tilde{n}_2^*) = z_\alpha。
该引理表明,如果在中期分析时调整了样本量,那么在最终分析中仍可以使用传统的统计量Z_2^*进行显著性水平为 \alpha的检验,前提是将界值 z_\alpha 替换为b(z_1, \tilde{n}_2^*) 。然而,秉持我们简洁明了的最终分析理念,我们更倾向于使用检验Z_2^* \geq z_\alpha而不是 Z_2^* \geq b(z_1, \tilde{n}_2^*)来拒绝原假设 H0。为了在不增加第一类错误的情况下实现这一目标,我们将“promising zone”定义为以下集合:
通过式(7)可以得知调整后的样本量\tilde{n}_2^*取决于z_1。请注意promising zone在数据揭盲前就已经定义好了。当在期中分析观察到Z_1=z_1处于\mathrm{CP}_{\delta_1}(z_1, \tilde{n}_2) \in \mathcal{P}中时,我们会将样本量从\tilde{n}_2 增加到\tilde{n}_2^*(z_1)。否则Stage Ⅱ的增量样本量将会保持在\tilde{n}_2 。那么如下所示:
因此可以得出如果我们使用传统的统计量可以很好的控制Ⅰ类错误。
那么如何找到promising zone P呢?有以下几个步骤
对于给定任意的\mathrm{CP}_{\delta_1}(z_1, \tilde{n}_2) \in (0, 1),根据公式(6)都可以得出具体的z_1。
然后可以根据公式(7)到(9)计算得出增加后的样本量n_2^*(z_1)。
根据1和2中分别得到的z_1和n_2^*(z_1),通过公式(11)得到界值b(z_1, \tilde{n}_2^*)。
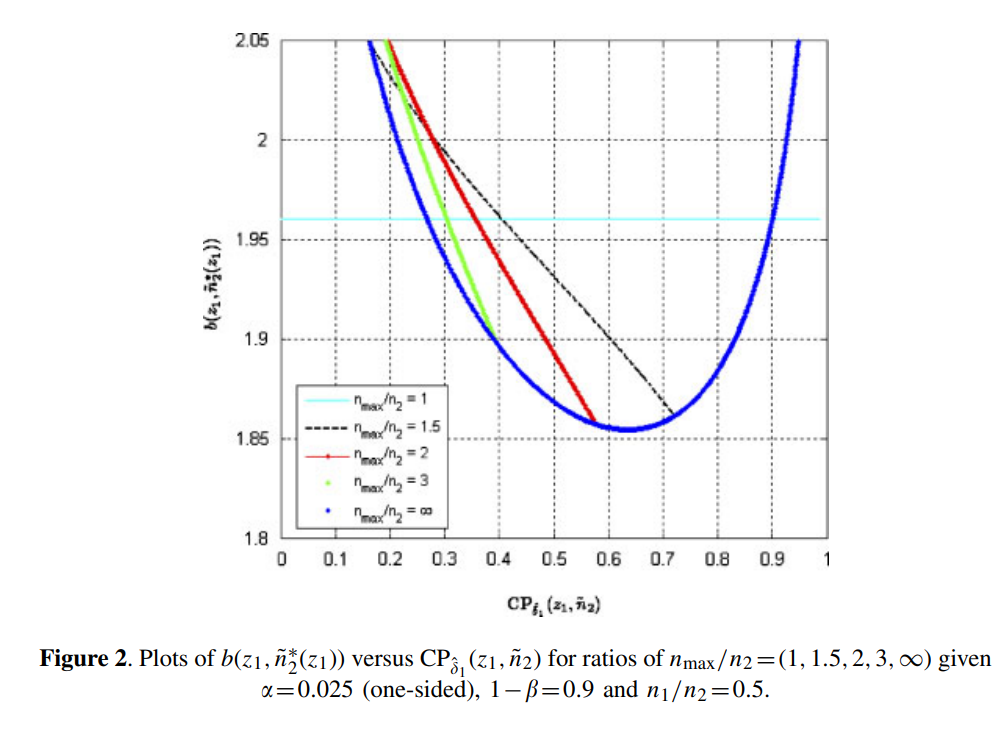
通过不断的重复1到3中的计算,可以绘制出以\mathrm{CP}_{\delta_1}(z_1, \tilde{n}_2)为X轴,b(z_1, \tilde{n}_2^*)为Y轴的图像。P就定义为在图中低于z_\alpha的部分。
如原文献中的Figure 2所示,如下:
3.3 Stage Ⅰ的有效和无效终止
上述提到的方法可以很容易就推广到两阶段的成组序贯设计中,并且允许在第一阶段前提前终止试验。假定有一个两阶段的、单侧的、显著性水平为α 的成组序贯试验,其包含无效性边界(a1)、疗效边界(b1,b2)以及累计的样本量(n1,n2),并满足:
当Z_1\geq b_1时,试验会因显著疗效而提前停止;当Z_1\leq a_1时,则因无效性而提前终止。令界值a_2=b_2,可以保证确保试验结束时有一个清晰明确的结论。若Z_2 \geq b_2,则拒绝H_0;否则接受H_0。式(14)确保该成组序贯的一类错误被控制在α,而式(15)保证其检验功效维持在1-β。只要将第3章中的z_\alpha替换为b_2,那么第3章所有结果可沿用。关于成组序贯中界值的计算方法和原理,可以看我原来写的blog:Group-sequential methods in clinical trials(1)。
4.小结
该文献[2]中提到了的方法简单易行且较为落地,基于不同的临床试验设计CP可以自动得出各个zone,以便有力的支持样本量调整的决策与调整后的样本量,并能较好的控制Ⅰ类错误。但在我在尝试后续落地实施时可能有以下的问题,a.在使用gsDesign包的ssrCP函数时,因为膨胀因子的存在,其样本量会有略微的增加;b.其提到了三种combination test策略,分别为z2NC, z2Z, z2Fisher,其似乎没有对应到本文献中提到的conventional test(z2Z好像为对应的方法,但是其画出来的图与原文献图中并不完全一样,我已通过WebPlotDigitizer验证,希望是我错了(╥﹏╥))c.关于用哪个消耗函数的问题(SFU)?等有时间再探索一下为什么吧。
5.参考文献
[1] 国家药监局药审中心《药物临床试验适应性设计指导原则(试行)》
[2] Mehta C R, Pocock S J. Adaptive increase in sample size when interim results are promising: a practical guide with examples[J]. Statistics in medicine, 2011, 30(28): 3267-3284.
[3] Cui L, Hung H M J, Wang S J. Modification of sample size in group sequential clinical trials[J]. Biometrics, 1999, 55(3): 853-857.
[4] Chen Y H J, DeMets D L, Gordon Lan K K. Increasing the sample size when the unblinded interim result is promising[J]. Statistics in medicine, 2004, 23(7): 1023-1038.
[5] Bauer P, Koenig F. The reassessment of trial perspectives from interim data—a critical view[J]. Statistics in medicine, 2006, 25(1): 23-36.
[6] Gao P, Ware J H, Mehta C. Sample size re-estimation for adaptive sequential design in clinical trials[J]. Journal of Biopharmaceutical Statistics, 2008, 18(6): 1184-1196.

